Did you know that your regex matching library may suck? Most libraries do, in certain circumstances, suck exponentially. This came to me as a great suprise when, a long time ago in the olden days before Google, iPods, and salmon skin leather, I was researching regex matching engines hoping to find a good one for use in a real-time system.
I’ll illustrate with a dusty ten-year-old picture from my Master’s Thesis:
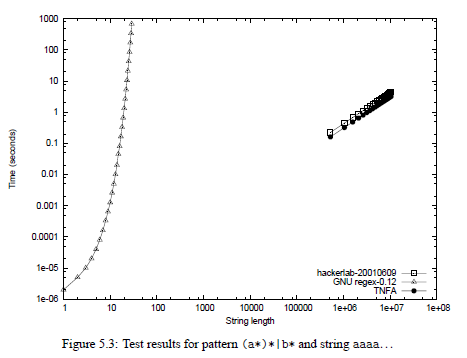
Horror! When I showed this to my colleagues, they didn’t believe it. Everyone just sort of assumed that the regex matchers they were using every day would, you know, work. The lesson here is that some regex matchers take potentially exponential time to find a match, while others always take linear time.
This picture may be over ten years old, but the world of regex matchers hasn’t really changed a whole lot. Virtually all libraries included in programming languages or their standard libraries use so called “backtracking” matchers and suffer from this performance issue. Python, Perl, PCRE, PHP, Java, and Ruby all come with a backtracking matcher. An infinite number of combinations of regexes and input strings exist which completely choke these matchers. For a detailed explanation, I recommend Regular Expression Matching Can Be Simple And Fast by Russ Cox, where he also has these better pictures (note difference in y axis scale in the two images):
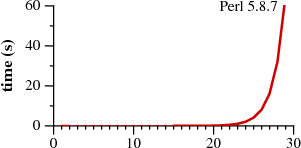 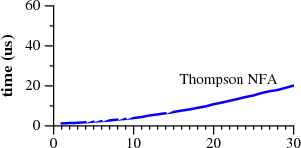 |
So when does this behavior matter? If you let untrusted users supply regexes, you may have a security issue in your hands, a denial-of-service the very least, if your library is bad. If you want to be sure your program won’t run out of memory or out of time, no matter what regex you throw at it, you cannot use the built-in libraries.
Luckily, there are some good efficient regex libraries which guarantee linear time matching and fixed memory usage:
- RE2 by Russ Cox, released 2010
- The Plan 9 regex matcher by Rob Pike, late 1980s, early 90s?
- TRE by me, released 2001
Others may exist, but these are in library form. RE2 is mostly PCRE compatible. TRE is POSIX compatible, and also supports approximate matching. The Plan 9 matcher has its own API.
So, there you have it. Parsing text is one of the things which is best done with a suitable theoretical background. You can’t parse HTML with regex, and you cannot efficiently parse a regular language with a backtracking matcher.
Related posts:
If you liked this, click here to receive new posts in a reader.
You should also follow me on Twitter here.
Comments on this entry are closed.
{ 5 comments }
Coincidentally this article is in the latest Computer:
http://www.computer.org/portal/web/csdl/doi/10.1109/MC.2010.80
Sorry, gotta quote, “The Plan 9 matcher has it’s own API. So, there you have it. Parsing text is one of the things which is best done with a suitable theoretical background”.
Apparently The Plan 9 matcher has _its_ own grammar as well. So, there, you have it. Parsing text is one of the things which is best done with a suitable theoretical background…
@Foo, oops, fixed that. It’s one of my many blind spots.
When quoting the images, you forgot to point out that one has time in microseconds, while the other in seconds.
@Blaisorblade, yeah, I figured the reader would notice the labels on the Y axis. But thanks, I added a note of this in the text.